네이버 뉴스에 접속해 오늘의 헤드라인을 추출해 도커에서 관리해 보자. 파이썬 크롤러를 소스코드를 작성하고 도커로 이미지화하고 필요할 때 컨테이너로 가져와 사용하는 컨셉이다.
물론, 간단한 파이썬 크롤링을 도커로 둘러살 필요는 없지만 어디까지나 도커실습이다. 응용 프로그램을 만들기 위한 실습이라고 보면 될 것이다.
1. 파이썬 코드 (뉴스 크롤링)
import requests
from bs4 import BeautifulSoup
def fetch_headlines():
url = "https://news.naver.com/section/104"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
response.raise_for_status() # HTTP 요청이 성공했는지 확인
soup = BeautifulSoup(response.text, "html.parser")
# 결과를 저장할 리스트
news_headlines = []
# 헤드라인 리스트 추출
headline_items = soup.find_all('li', class_='sa_item _SECTION_HEADLINE')
try:
for item in headline_items:
title_tag = item.find('a', class_='sa_text_title')
press_tag = item.find('div', class_='sa_text_press')
lede_tag = item.find('div', class_='sa_text_lede')
if title_tag:
title = title_tag.get_text(strip=True) # 제목 추출
link = title_tag['href'] # 링크 추출
else:
title, link = None, None
press = press_tag.get_text(strip=True) if press_tag else None # 언론사 추출
lede = lede_tag.get_text(strip=True) if lede_tag else None # 리드 내용 추출
news_headlines.append({
"title": title,
"link": link,
"press": press,
"lede": lede
})
return news_headlines
except requests.exceptions.RequestException as e:
print(f"HTTP 요청 중 오류 발생: {e}")
return []
if __name__ == "__main__":
headlines = fetch_headlines()
if headlines:
print("헤드라인 뉴스:")
for idx, lines in enumerate(headlines, start=1):
print(f"{idx}:{lines['title']}-{lines['press']}")
print(f"링크: {lines['link']}")
print(f"리드: {lines['lede']}\n")
else:
print("뉴스를 가져오지 못했습니다.")2. 파이썬 모듈 설치
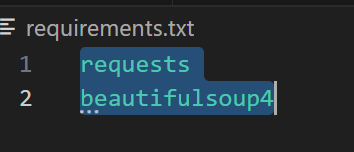
requirements.txt 파일을 만들어 크롤링에 필요한 requests, beautifulsoup4를 추가한다.
3.docker 환경 파일
# Python 베이스 이미지
FROM python:3.10-slim
# 작업 디렉토리 생성
WORKDIR /app
# 종속성 설치
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 크롤러 복사
COPY . .
# 실행 명령 설정
CMD ["python", "news.py"]4. 도커 이미지 만들기
n-news-crawler 이름으로 크롤링 프로그램을 저장한다.
docker build -t n-news-crawler .
5. 도커 컨테이너 실행
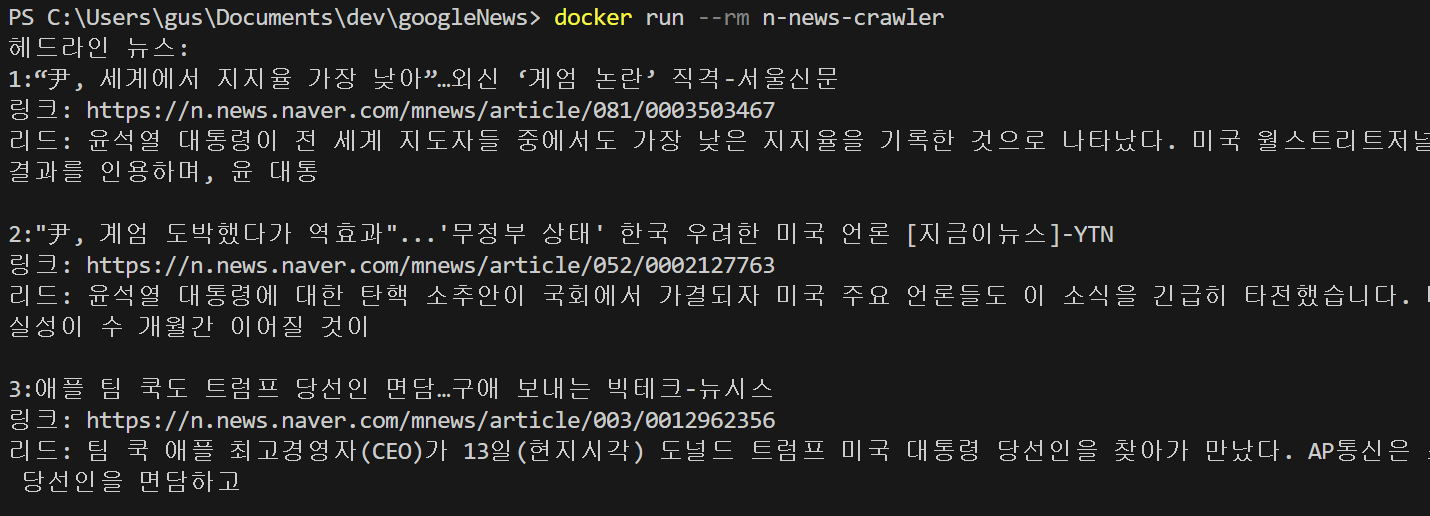
docker run --rm n-news-crawler # n-news-crawler를 도커에서 가져와 실행하고 완료되면 지운다.
'코드리뷰' 카테고리의 다른 글
| Docker 이해하는 세상에서 제일 쉬운 예제 만들기 - 기본 명령어 1 (0) | 2024.12.22 |
|---|---|
| 쿠바네티스 hello world 페이지 만들기 (1) | 2024.12.08 |
| 내 PC에 도커와 쿠바네티스 구축하기 (2) | 2024.12.01 |




댓글