웹 사이트 정보를 크롤링해 가져올 때 가끔 안 되는 경우가 있다. 대부분 접속자 헤더정보를 체크해 막아버리는 경우가 많다. 무분별한 봇 크롤링을 통한 부하를 방지하기 위함인데, 이럴 경우 어떻게 해야 할까?
네이버를 예를 들어보자. 네이버는 크롤링 시 헤더정보를 체크하지 않지만, 체크한다고 가정하고 회피코드를 작성해 보자.
1. 크롤링 시 내 pc 헤더정보 확인하기
[파이썬 코드]
[출력 결과]
{'User-Agent': 'python-requests/2.31.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
2. 웹 브라이저에서 네이버 접속해 헤더정보 확인하기
- 네트워크 > 이름 (naver) > User-Agent
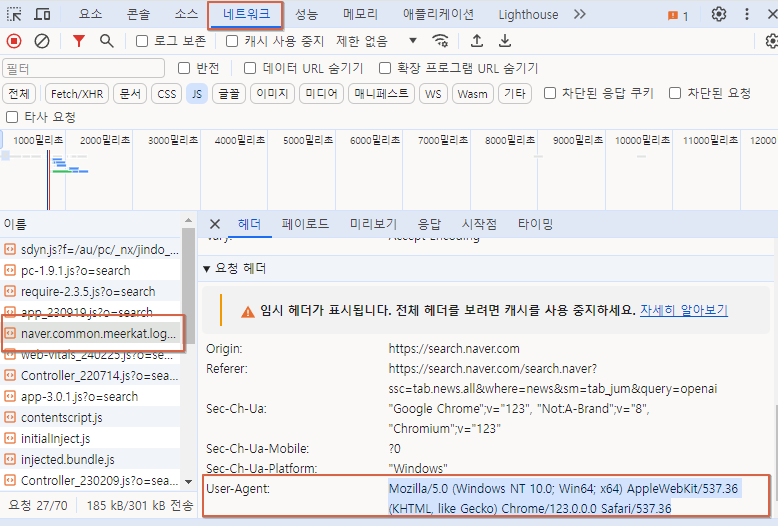
3. 소스코드에서 헤더 정보 변경해 네이버 크롤링 하기
(1) headers에 2번에서 찾은 User-Agent 정보를 복사해 붙여 넣는다.
(2) requests에 headrs인자를 추가해 값을 넣어준다.
keyword = input("KEYWORD : ")
url = f"https://search.naver.com/search.naver?ssc=tab.news.all&where=news&sm=tab_jum&query={keyword}"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'}
res = requests.get(url, headers=headers)
print(res.request.headers)(3) 출력하면 헤더정보가 바뀐 걸 확인할 수 있다.
{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
(myvenv) PS D:\dmad\code\coloso>
이렇게 하는 이유는?
앞에서 설명한 대로 비정상 접속으로 차단될 수 있기 때문에 마치 웹 브라우저에서 정상 접속한 것처럼 바꿔주는 것이다. 이런 과정을 통해 크롤링 시 사용하는 기본 정보를 확인하는 방법을 배우게 된다. 크롤링이랑 웹 사이트 정보를 임의로 가져오는 것이기 때문에 주도권이 데이터 수집하는 쪽에 있는 게 아니다. 사이트 개편이나 정책 변경으로 어느 순간에 접속이 차단되거나 엉뚱한 결과를 수집하게 되는 경우 왕왕 발생한다. 앵무새처럼 따라만 한다면 절대 이런 문제들을 해결하지 못할 것이다. 그래서 속속들이 체크하고 배워 응용방법을 깨우쳐야 한다.
'코드리뷰 > chatGPT(Python)코드' 카테고리의 다른 글
| 웹 크롤링 기초 - selenium 네이버 접속하기 (1) | 2024.03.23 |
|---|---|
| 웹 크롤링 기초 - 네이버 기사 제목 가져오기 (0) | 2024.03.22 |
| GRADIO 챗봇에 제휴링크 걸기 (1) | 2024.03.18 |




댓글